目次
はじめに:RAG導入の理想と現実
生成AIのビジネス活用が進むなか、有力なアプローチとして注目されているのがRAG(Retrieval-Augmented Generation:検索拡張生成)です。
RAGは、大規模言語モデル(LLM)に外部データの検索機能を組み合わせることで、AIが学習していない社内固有の情報も参照しながら回答できるようにする仕組みです。
セキュリティが担保された環境で、社内の膨大なナレッジをAIに参照させ、必要な情報を即座に引き出せるようになれば、属人化していた知識を組織の資産として活用しやすくなり、問い合わせ対応や情報検索の効率化も期待できます。
一方で、現実にはRAGを導入しただけで高い回答精度が得られるわけではありません。
PoCを進めたものの、多くの企業が「回答精度」の壁に直面しています。
- ・もっともらしく見えるが、内容は誤っている
- ・関連性の低い古い文書ばかり参照してしまう
- ・必要な情報があるはずなのに、「分かりません」としか返せない
その結果、「これでは業務では使えない」と判断され、構築したRAGシステムが十分に活用されないまま止まってしまうケースも少なくありません。
では、なぜ高性能なモデルを使っても、RAGの精度は思うように上がらないのでしょうか。
結論からいえば、原因はLLMそのものの性能だけではありません。
本記事では、RAGの精度が伸び悩む原因を「検索フェーズ」と「回答フェーズ」に分けて整理し、改善のために必要なデータエンジニアリングの考え方を解説します。
なぜ、RAGの精度は上がらないのか?(4つの壁)
RAGの精度が伸び悩む原因は、大きく分けると2つあります。
1つは、必要な情報を正しく見つけられないこと。もう1つは、見つけた情報をもとに正しい答えを生成できないことです。
つまり、RAGの課題は「検索フェーズ」と「回答フェーズ」の両方に潜んでいます。
【検索フェーズの課題】必要な情報が正しく見つからない
どれほど高性能なLLMを使っていても、参照する情報そのものが適切でなければ、正しい回答はできません。
まず問題になるのが、検索する段階で必要な情報にたどり着けないことです。
①検索用データの加工が不十分
社内データは、必ずしもLLMが扱いやすい形で存在しているわけではありません。
図表を多く含むPDF、セル結合の多いExcel、デザイン重視のPowerPointなど、人には理解しやすくても、LLMにとっては構造を正しく捉えにくい形式が少なくありません。資料でも、テキスト・画像・音声などの生データをそのままではなく、LLMが理解活用しやすい高品質な検索用データへ加工する必要があります。
② ユーザーの質問を適切に解釈できない
もう一つの壁は、ユーザーの自然な質問表現をそのままでは検索に活かせないことです。
たとえばユーザーが「社員規定について教えて」と尋ねても、実際の文書側では「就業規則」や「服務規程」といった名称で管理されていれば、単純な検索では必要な情報に届かない場合があります。
人にとっては同じ意味でも、システム側で表記ゆれや同義語を吸収できなければ、必要な情報を見つけ出せません。
【回答フェーズの課題】見つけた情報から正しい答えを作れない
検索によって関連文書を取得できたとしても、それだけで正しい回答が保証されるわけではありません。
次の壁は、取得した情報の中から何を採用し、どう答えに反映するかです。
③ 情報の優先順位付けや取捨選択ができない
検索結果の中に複数の関連情報が含まれているときに、どれを優先して使うべきかをうまく判断できない状態です。
たとえば
- ・最新版と旧版が混在している
- ・本文と注記が並んでいる
- ・一般ルールと例外ルールが同時に取得されている
といった場面で、回答に必要な情報だけを適切に絞り込めないと、もっともらしいが不正確な回答になってしまう場合があります。
④ 検索結果を正しく活用できない
さらに、必要な情報が取得できていても、それを回答生成の中で正しく使えなければ、誤答は防げません。
たとえば、
- ・検索結果に含まれる情報を十分に参照せずに推測で補ってしまう
- ・コンテキスト外の知識を混ぜてしまう
- ・複数の根拠を誤ってつなぎ合わせてしまう
など、検索結果を正しく活用できず、嘘の情報を出力してしまうといったことが起こります。
なぜ改善が進まないのか?
精度評価と改善サイクルの不在
RAGの精度課題を難しくしているのは、誤答の原因を特定しにくいことです。
実際、「回答がおかしい」と感じても、それが検索用データの問題なのか、質問解釈の問題なのか、情報選別の問題なのか、回答生成の問題なのかを切り分けられないケースは少なくありません。
その結果、改善は属人的な試行錯誤にとどまり、「何となくうまくいかない」状態から抜け出せなくなります。
RAGの精度向上には、ワークフロー全体を可視化し、どの工程で問題が起きているのかを把握したうえで、検索・回答・評価の各段階を継続的に見直していくことが欠かせません。
では、こうした精度の壁を越えるには何が必要なのでしょうか。
ポイントは、LLMそのものを替えることではなく、検索しやすく、選びやすく、答えに使いやすい形にデータを整備すること、そして改善を続けられる評価基盤を持つことです。
RAGの精度をどう高めるか
4つのフェーズで考える改善のポイント
RAGの精度向上は、単にLLMを高性能なものに置き換えれば実現できるものではありません。 重要なのは、検索しやすい形にデータを整え、質問意図に沿って必要な情報を取り出し、その中から適切な情報だけを使って回答を生成し、さらに継続的に評価・改善できる状態を作ることです。
ここでは、RAGの改善ポイントを4つのフェーズに分けて整理します。
① 検索フェーズ(前処理):データを、LLMが活用しやすい形に整える
RAGの精度を左右するうえで、最も重要なのが前処理です。 どれだけ検索ロジックや生成モデルを工夫しても、元となるデータが適切に整備されていなければ、正しい回答にはつながりません。
1.文書の構造化とチャンク設計
PDFを単なるテキストの羅列として抽出するだけでは、見出しと本文の関係、段落のまとまり、表や箇条書きの意味構造が失われてしまいます。
そのため、文書は見出しや段落の構造をできるだけ維持したまま、Markdownなどの扱いやすい形式へ変換することが重要です。
また、長い文書はチャンクと呼ばれる単位に分割して検索対象にしますが、単純に文字数で区切ると文脈が途切れ、必要な情報がうまく検索されないことがあります。
検索精度を高めるには、文字数ではなく、意味のまとまりを意識したチャンク設計が欠かせません。
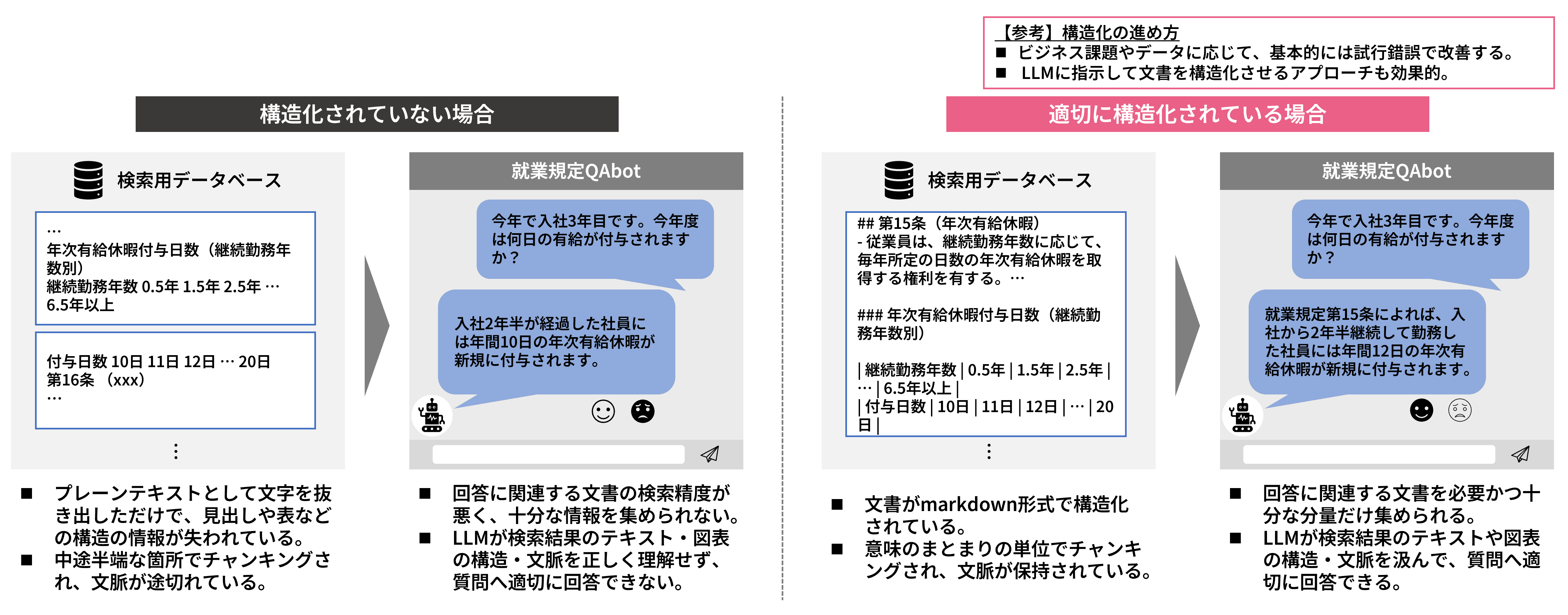
例:就業規則Qabot
2.非構造データの構造化
社内文書には、図面、表、スキャンPDF、画像化された帳票など、テキスト抽出だけでは扱いきれない情報も多く含まれます。
こうした非構造データをそのまま放置すると、検索対象に必要な情報が入らず、RAGの精度は頭打ちになります。
この課題に対しては、高精度なOCRを用いて文字情報を抽出したり、マルチモーダルLLMを活用して図表や画像の内容を説明文としてテキスト化したりすることで、検索可能なデータへ変換していくことが有効です。
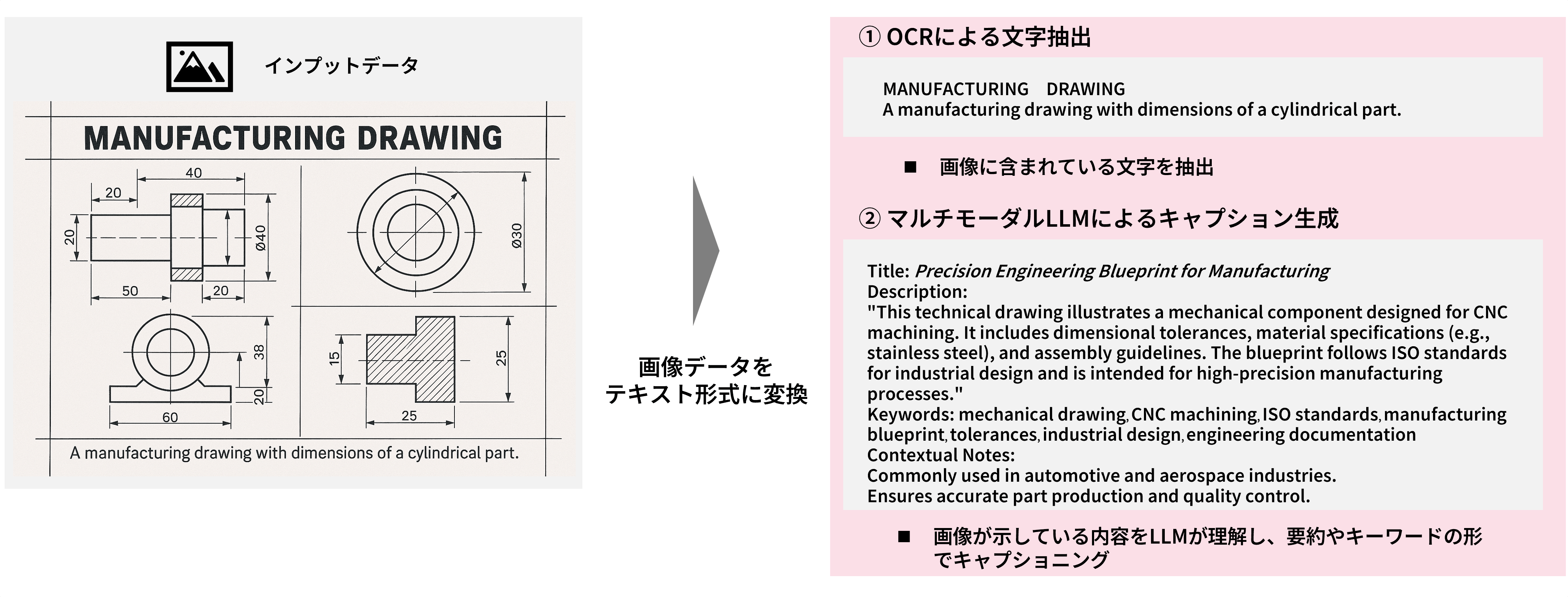
例:製造業における図面データのテキスト変換
② 検索フェーズ(クエリ処理):質問意図を汲み取り、必要な情報にたどり着けるようにする
ユーザーは、必ずしもシステムにとって都合のよい言葉で質問してくれるわけではありません。
そのため、入力された質問をそのまま検索にかけるのではなく、AI側で意図を補完し、適切な検索クエリへ変換する工夫が必要です。
1.ハイブリッド検索
検索には、キーワード検索が向くケースと、ベクトル検索が向くケースがあります。
たとえば「型番:A-123」のように完全一致が重要な問い合わせではキーワード検索が有効です。一方で、「PCが壊れた」のような表現では、意味の近さを捉えるベクトル検索のほうが適しています。
この両者を組み合わせたハイブリッド検索を採用することで、検索の取りこぼしを抑えやすくなります。
2.クエリ拡張
ユーザーの質問は、しばしばあいまいです。たとえば「あの件どうなってる?」という質問だけでは、検索に必要な条件が不足しています。
こうした場合には、直前の会話履歴や関連文脈をもとに、AIが内部的に「A社プロジェクトの進捗はどうなっていますか?」のように検索向けの表現へ補完したり、同義語や関連語を追加して検索範囲を広げたりする処理が有効です。
クエリ拡張は、質問意図を検索に正しくつなぐための重要な手段です。
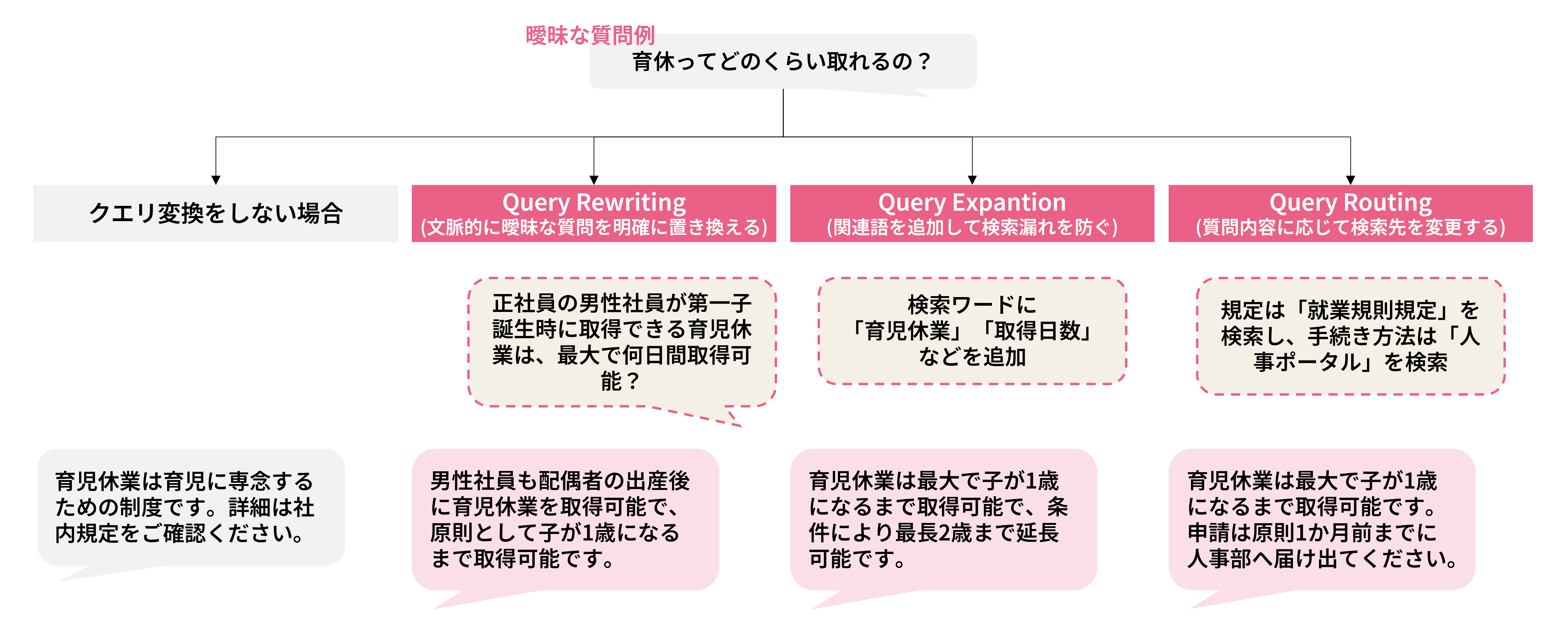
例:あいまいな質問に対するクエリ変換
③ 回答フェーズ:不要な情報や不適切な回答を防ぐ
検索で関連情報を取得できたとしても、それをそのままLLMに渡せばよいわけではありません。 回答品質を左右するのは、検索結果の中から何を使い、どのような条件で答えさせるかです。
1.リランクによる選別
検索エンジンが取得した文書の中には、関連性の高いものもあれば、ノイズに近いものも含まれます。
そのため、取得結果を改めて質問との関連度で並べ替え、本当に必要な情報だけを上位に絞り込んでからLLMに渡す処理が重要になります。
このリランクを入れることで、不要な文書や古い情報が回答に混ざるリスクを抑えやすくなります。
2.ガードレイルによる回答制御
RAGでは、検索結果に根拠がある範囲だけで答えさせる、根拠が不足している場合は無理に推測させない、といった制御も重要です。
こうしたルールを設けずに回答生成を任せると、もっともらしいが根拠の薄い回答が返るリスクが高まります。
たとえば、参照した文書に根拠がない場合は「分かりません」と返す、出力形式を固定する、禁止語や不適切表現を抑制するといったガードレイルを組み込むことで、回答の安定性を高めることができます。
3.ファインチューニング
特定業界の専門用語や社内固有の言い回し、あるいは厳密な回答フォーマットへの準拠が求められる場合には、モデル自体の追加学習が有効なこともあります。特に、医療、法律、金融など、高い専門性や一貫した出力品質が求められる領域では、長期的な精度向上策の一つとして検討に値します。
ただし、ファインチューニングはRAGにおける検索精度や参照情報の妥当性そのものを直接解決する手段ではありません。
社内文書の最新版を正しく見つけることや、必要な情報だけを適切に選び出すことは、あくまで検索・選別・制御の設計で解決すべき課題です。
そのため、まず優先すべきは検索・選別・制御の改善であり、ファインチューニングはそのうえで出力品質を補完的に高める選択肢として位置づけるのが現実的です。
④ 評価・改善フェーズ:作って終わりにしないための仕組みを持つ
RAGは、構築した時点で完成するものではありません。
運用を通じて誤答や取りこぼしを把握し、どこに問題があるのかを切り分けながら改善を重ねていくことが重要です。
1.評価フレームワークの導入
「何となく精度が低い」という感覚的な評価だけでは、改善ポイントは見えてきません。
たとえば、正解となる文書が検索できているか、検索結果に基づいて忠実に回答できているか、といった観点で評価指標を置くことで、どの工程に課題があるかを把握しやすくなります。
2.トレーサビリティとHuman-in-the-loop
RAGの改善では、単に評価スコアを見るだけでなく、実際の利用者や業務担当者の判断を改善サイクルに組み込むことが重要です。
これが Human-in-the-loop の考え方です。
たとえば、利用者が回答に対して「正しかった」「根拠が不足している」「古い情報を参照している」といったフィードバックを返せるようにしておけば、システム上の評価だけでは捉えにくい実務上の問題を蓄積できます。
さらに、そのフィードバックをもとに、運用担当者が検索結果・参照文書・回答内容を確認することで、課題が前処理にあるのか、検索ロジックにあるのか、回答生成にあるのかを切り分けやすくなります。
重要なのは、フィードバックを集めること自体ではなく、それを検索対象データの修正、メタデータ整備、チャンク設計の見直し、検索条件やガードレイルの調整といった具体的な改善につなげることです。
こうした人の評価とシステム改善のループを継続的に回すことで、RAGは実運用に耐える精度へと近づいていきます。
まとめ:TDSEのアプローチ
生成AIを業務で活用するうえで、RAGは非常に有効なアプローチです。
社内ナレッジを参照しながら回答できるようにすることで、汎用モデルだけでは届かない実用性を引き出しやすくなります。
一方で、RAGの精度向上に近道はありません。
データの特性に合わせた前処理、質問意図を踏まえた検索設計、不要な情報を混ぜない回答制御、そして評価にもとづく継続的な改善。この積み重ねこそが、PoCで終わらず、業務で使えるRAGを実現するための現実的な道筋です。
また、生成AIを取り巻く技術は変化が速く、利用するモデルや構成も今後見直しが前提になります。
だからこそ重要なのは、その時点のモデル性能に依存しすぎることではなく、データ整備・検索・回答制御・評価改善の仕組みを持ち、継続的に精度を高められる状態を作ることです。
TDSEは、データサイエンスとエンジニアリングの両面から、RAGの構築・改善をご支援しています。
社内文書や業務データの特性を踏まえた前処理設計、検索ロジックや回答制御の最適化、評価基盤の整備まで、一連のプロセスを見据えた支援が可能です。
また、TDSEはDifyの公式販売・構築パートナーとして、Dify Enterpriseの販売から環境構築、活用支援、研修、テクニカルサポートまで提供しています。
Difyを活用したRAGや生成AIアプリの構築支援も行っており、エンタープライズ企業を含む企業導入の知見を踏まえて、要件整理から実装・運用までご相談いただけます。
- ・PoCまでは進んだが、精度が伸び悩んでいる
- ・社内データが複雑で、RAGに載せる前処理に悩んでいる
- ・Difyで構築を進めたいが、業務で使えるレベルまで設計・運用できるか不安がある
このような課題をお持ちでしたら、ぜひTDSEにご相談ください。
現状の課題を整理したうえで、RAGの精度向上に向けて、どこから手を打つべきかをご提案します。



